Note: Supporting code and data are available here.

Figure 1. An illustration of Multimodal Prompting: an arbitrary composition of images and text can be used as a prompt to the Stable Diffusion model using the method presented in this article.
In the past few months, we have experienced groundbreaking progress on the front of image generation models. While some of these models have been available behind black-box user interfaces (or only for fixed prompts) ( Citation: Yu, Xu et al., 2022 Yu, J., Xu, Y., Koh, J., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B., Hutchinson, B., Han, W., Parekh, Z., Li, X., Zhang, H., Baldridge, J. & Wu, Y. (2022). Scaling autoregressive models for content-rich text-to-image generation. arXiv. https://arxiv.org/abs/2206.10789. ; Citation: Ramesh, Dhariwal et al., 2022 Ramesh, A., Dhariwal, P., Nichol, A., Chu, C. & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv. https://arxiv.org/abs/2204.06125. ; Citation: Gafni, Polyak et al., 2022 Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D. & Taigman, Y. (2022). Make-a-scene: Scene-based text-to-image generation with human priors. arXiv. https://arxiv.org/abs/2203.13131. ) , some of them ( Citation: Rombach, Blattmann et al., 2021 Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. (2021). High-resolution image synthesis with latent diffusion models. arXiv. https://arxiv.org/abs/2112.10752. ) have been open-sourced with practically no restrictions! This has led to a tremendous surge in the use, analysis and extension of models like Stable Diffusion which is now being used for very creative applications such as infinite image outpainting, textual inversion, and so on. ( Citation: Gal, Alaluf et al., 2022 Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A., Chechik, G. & Cohen-Or, D. (2022). An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv. https://arxiv.org/abs/2208.01618. ) .
This article presents yet another extension to the Stable Diffusion model for image generation: a simple and fast strategy towards prompting Stable Diffusion with an arbitrary composition of image and text tokens. The use of multimodal prompts can be justified for the following reasons:
- Achieving high quality, desirable outputs from image generation models requires rigorous prompt tuning. While the community has reverse-engineered several interesting tricks for working with image generation models, this leads to a bad user-experience.
- In zero-shot settings, when either the user or the model comes across a concept that is not within their vocabulary or too cumbersome to describe, the model may be better suited with processing the prompt if it can be “shown” the new concept and instructed to manipulate the new concept in textual format.
Figure 1 shows an example of our method in action and more examples are shown below. In the following sections, we will look closer into how this can be achieved using a simple technique.
Method
Enabling multimodal prompting requires the underlying model to have a joint understanding of the different modalities. The straightforward solution for this would be to train or finetune Stable Diffusion so that its conditioning model can input multiple modalities, so that its outputs can be continued to use as before. Another method for this could be to use textual inversion ( Citation: Gal, Alaluf et al., 2022 Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A., Chechik, G. & Cohen-Or, D. (2022). An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv. https://arxiv.org/abs/2208.01618. ) : we can finetune the model to represent each of the non-text concepts in the prompt as textual tokens, and use the newly learned tokens to replace the images in the prompts. However, in this article, we will look at a simpler strategy that requires no training or finetuning in any way, with negligible additional overhead in comparison to the original Stable Diffusion.
The high level overview of our method is as follows:
-
Maintain a rich corpus of prompts (or sub-prompts) that can textually explain various aspects of the images in any prompt in detail;
-
For each image in the prompt, find the nearest neighboring text prompts in the above dataset by projecting the image and the above curated text prompts into the pooler representation of a text-image alignment model, such as CLIP ( Citation: Radford, Kim et al., 2021 Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G. & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv. https://arxiv.org/abs/2103.00020. ) ;
-
A meaningful prompt can be obtained by concatenating a diverse set of nearest neighbors obtained: this is achieved by using a popular reranking algorithm, Maximum Marginal Relevance (MMR) ( Citation: Carbonell & Goldstein, 1998 Carbonell, J. & Goldstein, J. (1998). The use of MMR, diversity-based reranking for reordering documents and producing summaries. Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval. ) over the nearest neighbors found above;
-
Replace each image in the prompt with its “translated” text to obtain a text-only prompt which can be used to prompt Stable Diffusion without any finetuning or training.
Let us look at each piece of this method in more detail.
Data: Curating an index of text prompts
Our method requires being able to retrieve text prompts that can adequately describe any image used in a prompt. Towards this, we use a processed version of Simulacra Aesthetic Captions ( Citation: Pressman, Crowson et al., 2022 Pressman, J., Crowson, K. & Contributors, S. (2022). Simulacra aesthetic captions (Version 1.0). Stability AI. https://github.com/JD-P/simulacra-aesthetic-captions. ) which is a curated dataset of over 40K prompts written by users of image-generation models.
Most prompts in this datset are long-winded and highly detailed such that they only describe their respective generated images. Thus, this set of prompts may not be able to describe a new image that has details different from any image that this dataset describes. So, we chunk each prompt in the dataset into smaller $n$-grams (in our experiments, we fix $n = 4$) such that each $n$-gram can be expected to describe only an atomic detail of some image. Thus, in expectation, combining different $n$-grams across the dataset should expand the scope of images describable by the dataset. While blind composition of random $n$-grams from the dataset may not lead to prompts that are intelligible or even grammarly correct, we can expect our retrieval strategy to obtain a diverse set of terms in the composition such that each provides meaningful signal to Stable Diffusion about what has to be generated.
For example, the prompt 'A crowded subway car, the fluorescent lights flickering and casting an eerie glow on the people inside' will be mapped to a list of $4$-grams as: ['A crowded subway car', 'crowded subway car, the', 'subway car, the fluorescent', ..., 'on the people inside'].
Mapping images to text
Given any image, we are interested in retrieving a set of $n$-grams such that composing them adequately describes the image. An intuitive way for doing this is to find the nearest neighbors texts to a query image in the representation space of a text-image alignment model. So, we utilize CLIP’s pooled representation space to perform cross-modal nearest-neighbor search where the query is the image to be descibed and the index of candidates comprises all the $n$-grams curated above.
Simply picking the top-$k$ neighbors from a nearest-neighbor search described above might lead to uninteresting results. For example, if the top-$k$ text neighbors describe the same aspect of an image, the resulting combination of them will not sufficiently describe the query.
Towards mitigating this, we use a popular re-ranking algorithm, called Maximum Marginal Relevance (MMR) to pick a diverse set of $n$-grams from the top-$k$ neighbors, which when concatenated together, describe the image more meaningfully. MMR iteratively selects documents from the top-$k$ neighbors, such that each new selected document introduces new information while still staying relevant to the query. Specifically, given the collection of top-$k$ documents, $\mathcal{R}$, a set of already selected documents, $\mathcal{S}$, and a query $\mathcal{Q}$, MMR augments the set of selected documents as:
$$\mathcal{S} \leftarrow \mathcal{S}\ \ \cup\ \ \left\lbrace\argmax_{D_i \in \mathcal{R} \backslash \mathcal{S}} \left[ \lambda sim_1(\mathcal{Q}, D_i) - (1 - \lambda) \max_{D_j \in \mathcal{S}} \left[ sim_2(D_i, D_j) \right] \right]\right\rbrace,$$
where, $\lambda$ is a hyperparameter that allows us to trade-off between relevance and diversity. Simply put, MMR selects a new document such that it has high relevance to the query (as measured using $sim_1$) and also diverges from the already selected documents in $\mathcal{S}$ (as measured using $sim_2$). In our experiments, we set $k=100$, $\lambda=0.7$, and $sim_1$ and $sim_2$ are cosine similarities between a $4$-gram and the image and another already selected $4$-gram respectively as measured using the pooled representations from CLIP.
Figure 2 below shows a schematic of this approach.

Figure 2. Finding meaningful $n$-grams from the curated dataset. This involves doing a nearest neighbor search using CLIP and reranking the nearest neighbors to ensure sufficient diversity among the top few items in the ranklist.
Generating prompts
Having obtained a ranklist of text prompts such that the top few prompts are relevant and sufficiently diverse, we can compose the top-$m$ of these reranked top-$k$ items by simply concatenating them. More sophistacted approaches for combining these which retain grammatic correctness and better capture context of the remaining prompt are left as future work.
In our experiments, we found that $m$ can be used to weight different images in the prompt relative to each other. Figure 3 below demonstrates the effect of varying $m$ across images in the same prompt. Finally, $m = 4$ was found to be an average value and assigning weights to images relative to this value would change their relative importance for generation.
For example, the replacement prompt for the image in Figure 2 would be (with $m = 4$): "tropical beach covered in water unsplash 4k photograph pastel palette matte painting pink at sunset".
Results
We can perform the above procedure for each image in the prompt and convert our multimodal prompt to a text-only prompt. This translated text can then be used to prompt the Stable Diffusion model as originally intended for their txt2img variant.
Figure 3 below shows some qualitative results from this method. Stable Diffusion is used to generate these images using the PLMS sampler over 200 steps.

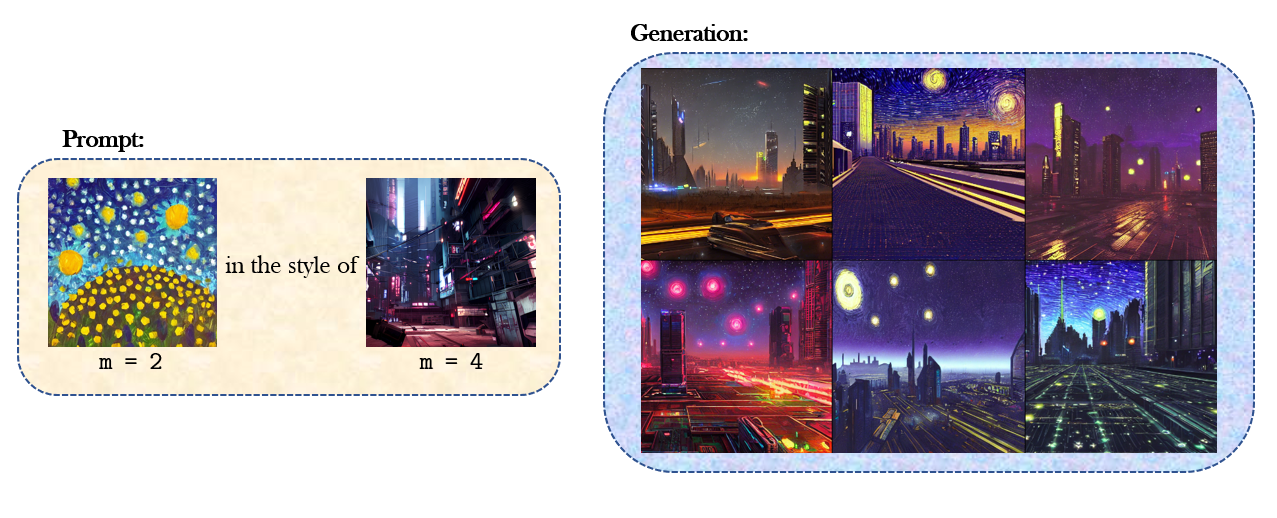


Figure 3. Qualitative results from our method. The prompts are shown on the left and 6 sampled generations are shown on the right. For the bottom 3 illustrations, we see the effect of varying $m$: weighting different images in the prompt reflects the corresponding details in the generation while staying true to the desired weighting.
Future Work
Evaluation of the above work can be along the following fronts of (1) latency overhead when compared with the text-only version of the model and textual inversion for the same prompt, and (2) measuring the effectiveness of proposed retrieval algorithm; for example, given a text-image paired dataset, we can measure precision-recall scores for being able to retrieve $n$-grams belonging to the original pair.
While this method is simple and effective, there are many potential directions for enabling multimodal prompting more deeply by changing how we condition the diffusion model:
-
Conditioning with aligned representations: The above method required to perform retrieval to handle the gap between the text representations and images representations from the prompts. If we train the image generation model to generate images by conditioning using language-image aligned representations, the prompt could be made to vary flexibly between images and text.
-
Training with multimodal prompts: Multimodal prompts can also be handled using a multimodal conditioning model with separate branches for different modalties. By including positional information alongwith the specific text/image inputs, we can allow the model to identify the sequential information and relationships across modalities. Note that this requires careful curation of a datset with paired (multimodal prompt, target image) pairs.
References
-
Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G. & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv. https://arxiv.org/abs/2103.00020.
-
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C. & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv. https://arxiv.org/abs/2204.06125.
-
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. (2021). High-resolution image synthesis with latent diffusion models. arXiv. https://arxiv.org/abs/2112.10752.
-
Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D. & Taigman, Y. (2022). Make-a-scene: Scene-based text-to-image generation with human priors. arXiv. https://arxiv.org/abs/2203.13131.
-
Carbonell, J. & Goldstein, J. (1998). The use of MMR, diversity-based reranking for reordering documents and producing summaries. Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval.
-
Yu, J., Xu, Y., Koh, J., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B., Hutchinson, B., Han, W., Parekh, Z., Li, X., Zhang, H., Baldridge, J. & Wu, Y. (2022). Scaling autoregressive models for content-rich text-to-image generation. arXiv. https://arxiv.org/abs/2206.10789.
-
Pressman, J., Crowson, K. & Contributors, S. (2022). Simulacra aesthetic captions (Version 1.0). Stability AI. https://github.com/JD-P/simulacra-aesthetic-captions.
-
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A., Chechik, G. & Cohen-Or, D. (2022). An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv. https://arxiv.org/abs/2208.01618.